일본에게 의존도가 높았던 장비를 국산에서 직접 개발한 것은 굉장한 발전이다. 또한 마이크로 쏘를 국산화하여 1년에 900억원 내외의 비용을 절감했다는 점에서 그 비용을 다른 곳에 투자하여 더 많은 발전을 이룰 수 있을 것이라 생각되어 아주 희소식이라 생각한다.
한미 반도체는 지난 6월에도 국내 최초로 듀얼척 쏘를 국산화하였다. 듀얼척 쏘는 1회 작동으로 칩을 2장 절단할 수 있어 후공정 효율이 싱글척 쏘에 비해 높다. 이번에는 듀얼척 쏘에 이어 마이크로 쏘를 국산화한 한미반도체가 다음엔 어떤 발전으로 우리나라에 기여할지 기대된다. 일본 제조사 디스코가 웨이퍼 절단 기술에 한 눈 판 사이 독점하던 시장을 벗어나 국산화를 한 점이 굉장히 대단하다고 생각한다.
시간이 더 오래걸리는 디스코로의 공급보다 더 저렴한 가격과 빠른 공급이 기대되어 반도체 회사들도 더 큰 발전을 할 수 있을 것으로 생각된다.
모르는 단어
후공정 : 반도체의 8대 공정 중에서 마지막 두 공정인 전기적 패키지 공정과 패키지 공정을 말한다.
이전 글에서 설명한 API와 logistic regression을 이용하여 얼굴 비대칭성을 계산하고 정상인과 환자 사진을 학습시켜 결과를 예측하도록 하였다. 뇌졸중 자가진단에 머신러닝을 사용하기 위해선 3단계의 과정이 필요하다. 첫 번째는 비대칭성 계산, 두 번째는 학습, 세 번째는 예측이다. 이 세 가지 단계는 다음과 같이 이루어져있다.
비대칭성 계산
우리가 구현하고자 하는 기능을 위해선 얼굴의 눈, 코, 입을 인식하고 위치를 알 수 있는 API가 필요했다. 이 API는 github에 있는 cv2, dlib를 사용한 코드를 얻어올 수 있었다. API를 이용하여 아래 그림처럼 얼굴의 좌표를 얻을 수 있다.
뇌졸중의 초기 증상중 하나인 안면마비를 검증하기 위해 안면마비 환자들의 특징을 알아보았고 환자가 웃었을 때 왼쪽과 오른쪽의 비대칭성을 통해 의사가 판단한다는 것을 알 수 있었다. 따라서 얼굴의 좌표를 이용해 얼굴 중앙을 중심으로 3가지를 특징을 종합하여 왼쪽과 오른쪽의 비대칭성을 계산해보았다. 특징은 다음 3가지이다. 괄호 안에 있는 숫자는 아래 사진에서의 좌표 번호이다.
안면 비대칭을 확인하기 위한 거리 계산
1. 중심(34)에서 왼쪽 눈 끝(37)까지의 거리 : 중심(34)에서 오른쪽 눈 끝(46)까지의 거리
2. 중심(34)에서 왼쪽 코 끝(32)까지의 거리 : 중심(34)에서 오른쪽 코 끝(36)까지의 거리
3. 중심(34)에서 왼쪽 입술 끝(49)까지의 거리 : 중심(34)에서 오른쪽 입술 끝(55)까지의 거리
얼굴의 비대칭성이 심할수록 왼쪽과 오른쪽 거리의 차이가 더 커질 것이다. 따라서 비대칭성을 표현하는 수는 (작은 거리)/(큰 거리)를 이용하여 비율로 나타내었다. 즉 이 값이 1에 가까울수록 얼굴이 대칭적이고 1에서 멀어질수록 얼굴이 비대칭적이라는 말이다. 눈, 코, 입에 (작은 거리)/(큰 거리) 식을 이용하여 각각 계산하고 그 합을 더하였다. 따라서 3가지를 합하므로 3에 가까울수록 얼굴이 대칭적이라는 것이다.
학습
실제 환자 사진과 정상인 사진으로부터 계산한 비대칭성을 나타낸 수를 이용하여 학습을 시켜야한다. 실제 환자 얼굴은 개인정보이기 때문에 많은 사진을 구할 수 없었다. 따라서 크롤링을 이용해 구글에서 찾을 수 있는 환자의 사진을 최대한 많이 모아보았다. 그 결과 160장의 사진을 구할 수 있었다. 정상인의 사진도 비슷한 개수로 구글링을 통해 154장을 구하여 총 314장의 사진으로 학습을 진행하였다. 1번 과정을 통해 얼굴의 비대칭성을 수로 표현할 수 있었다. 그 다음엔 각 사진이 하나의 숫자로 표현되기 때문에 logistic regression의 Classification을 이용하여 뇌졸중이 의심된다(1) 아니다(0)로 판단할 수 있다. 학습 과정은 다음과 같다.
- linear regression(선형 회귀)
선형 회귀로 환자와 정상인으로부터 계산한 비대칭성을 나타내는 수들의 분포로부터 최적의 직선을 하나 만든다. 수치미분을 하며 학습시킬 비대칭성 수들로부터 최적의 직선을 만든다. 이 직선의 기울기가 W, y절편이 b이다. x가 뇌졸중이 의심되는지 판단하고자 하는 사람의 비대칭성을 계산한 수라고하면 (W*x + b) 값은 학습한 점들로부터 유추되는 예측 값이다. 매번 학습시킬 수 없기 때문에 학습한 결과인 W값과 b값은 파일에 저장하여 예측을 할 때 사용된다.
- Classification(분류)
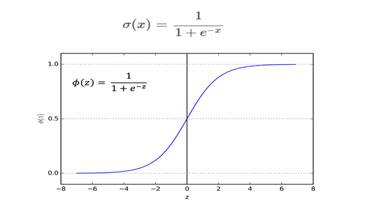
과정 1에서 한 선형 회귀의 결과 값은 뇌졸중이 의심되는지 판단하기 위해 1 또는 0의 값만을 가져야한다. 따라서 분류에 자주 사용되는 함수인 sigmoid 함수를 이용하여 1과 0 사이의 값으로 나타낸다. sigmoid함수는 오른쪽과 같은 수식과 함수 그래프로 나타난다. 따라서 sigmoid함수의 결과 값이 0.5보다 크면 안면마비일 확률이 높다는 뜻이므로 1을 리턴하고 0.5보다 작으면 안면마비일 확률이 낮으므로 0을 리턴한다.
sigmoid 함수 수식과 그래프
- 학습 과정 구성도
train.py 구성도
예측
이제 학습된 결과를 이용해 사용자로부터 사진을 받으면 안면마비인지 예측할 수 있다. 우선 사진의 비대칭성을 나타내는 수를 구하여 Wx + b값을 얻는다. 그 다음 결과 값을 sigmoid함수에 넣어 0.5보다 클 경우 안면마비로 판단, 0.5보다 작을 경우 안면마비가 아닌 것으로 판단할 수 있다. 결과를 예측하는 과정은 아래와 같은 구성도와 같이 동작한다.
result.py 구성도
예시
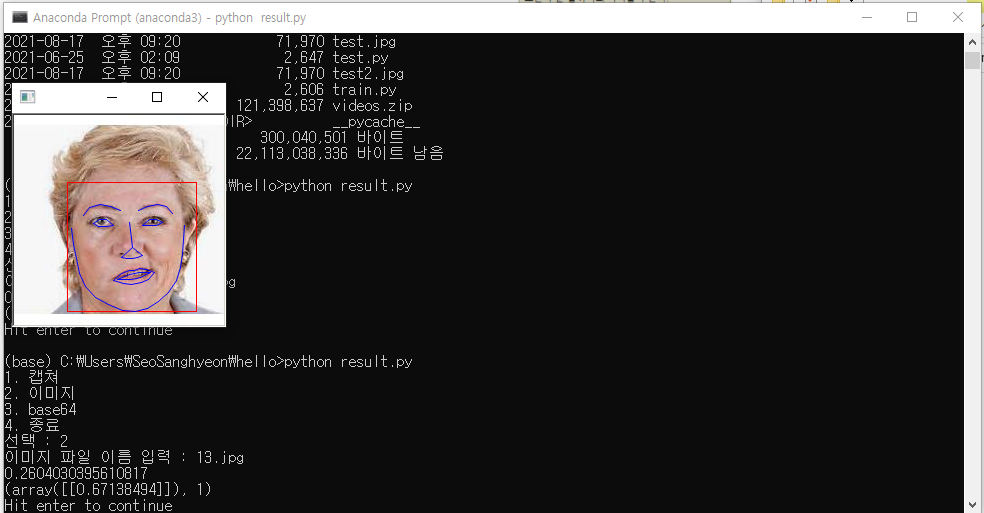
환자 사진 예시
환자 사진을 예측한 결과이다. 아래서 세 번째 줄에 있는 0.2604..라는 값은 0이 완전 대칭이라고 할 때 얼마나 비대칭적인지를 나타낸 값이다. numpy배열로 나타난 아래서 두 번째 줄의 첫 번째 원소인 0.67138494는 sigmoid함수 결과 값으로 0.5보다 클 경우 뇌졸중으로, 0.5보다 작을 경우 정상으로 나온다. 0.67138494은 0.5보다 크므로 뒤에 1이라는 결과가 나와 뇌졸중 의심으로 판단한 것을 알 수 있다.
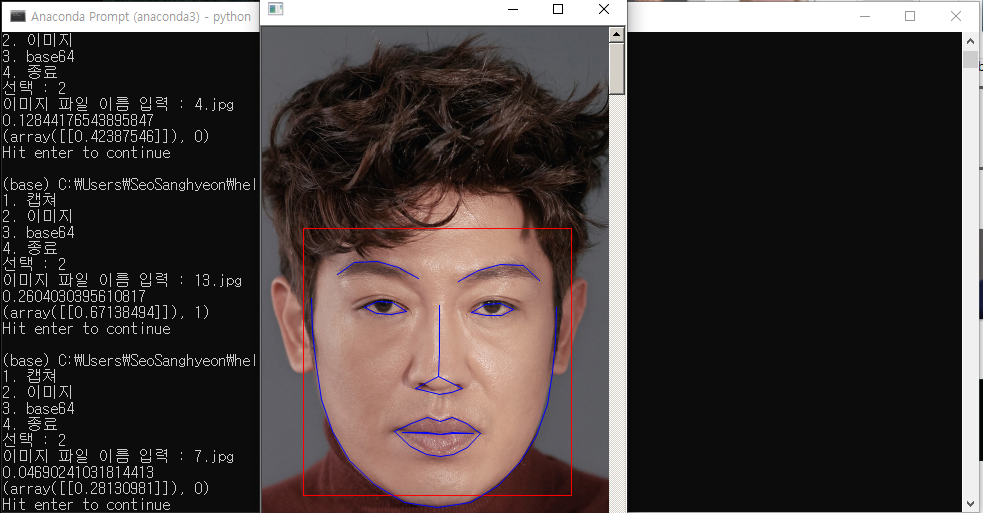
정상인 사진 예시
정산인 사진을 예측한 결과이다. 환자 사진과 비교해보면 0.0469..라는 값으로 0에서 크게 벗어나지 않은 것을 볼 수 있다. 또 0.28130981의 sigmoid 결과값은 0.5보다 훨씬 작은 수치로 뇌졸중 의심이 되지 않는다고 예측한 것을 알 수 있다.
머신러닝과 딥러닝API를 이용하여 안면비대칭을 진단하는 과정은 이렇게 이루어진다. 이제 사용자가 이용할 수 있게 웹사이트에 올려 사진을 받고 결과를 보여주는 작업이 남았다.
사용자가 언제 어디서든 쉽게 사용할 수 있도록 하는 것이 중요한 사안이었기 때문에 웹페이지에 접속해 검사를 진행할 수 있도록 프로그램을 구현하였다. 웹페이지에 접속을 하게 되면 사용자는 사용하고 있는 전자기기에 따라 PC의 웹 카메라 또는 스마트폰의 전면 카메라를 통해 자신의 얼굴 사진을 캡처 하고 이 사진은 서버에 전송된다. 장고 웹 프레임워크를 사용하는 서버에 전달된 사진은 머신 러닝으로 학습된 함수 값에 따라 안면 비대칭에 근거한 뇌졸중 의심 여부를 판단하여 사용자가 분석 결과를 볼 수 있도록 웹페이지에 출력된다.
웹페이지와 UI는 React라는 JS 라이브러리를 사용하여 구현하였으며 검사를 위한 사진 캡처, 프로그램에 대한 설명과 같은 기능을 제공한다. 사용자는 웹페이지에 접속하자마자 별 다른 과정 없이 간편하게 사진 캡처를 하고 결과 분석을 열람할 수 있다.
사용자가 자신의 얼굴을 캡처한 사진을 제출하게 되면 이는 장고 웹 프레임워크로 구현한 서버로 전송된다. 해당 사진은 서버의 DB에 저장되며 python으로 구현한 분석 함수의 입력 값으로 주어지게 된다. 분석 결과가 함수로부터 반환되면 이는 서버로부터 다시 웹페이지로 전송되어 사용자가 볼 수 있도록 결과와 함께 설명이 출력된다.
캡처한 사진이 담고 있는 얼굴을 분석하기 위해 이미지를 처리하는 라이브러리인 OpenCV와 dlib를 사용하였다. 이 중 사진에서 얼굴을 인식하는 face detector와 눈, 코, 입 등 얼굴의 주요 부위를 인식하는 landmark predictor라는 기능을 사용하였다. Landmark predictor는 사진에서 인식한 얼굴의 주요부위를 68개의 좌표 값으로 출력하며 해당 값들을 통해 얼굴의 전체적인 비대칭 비율을 계산하였다.
뇌졸중으로 인한 안면 마비 증상을 보이는 환자들의 얼굴 사진들과 정상인의 얼굴 사진들을 미리 구해 앞서 언급한 비대칭 비율을 계산하여 logistic regression과 classification을 활용해 학습 과정을 진행하였다. 학습된 결과를 바탕으로 새로운 얼굴 사진이 주어졌을 때 sigmoid 함수를 이용해 뇌졸중 의심 여부를 판단하여 결과 값을 반환한다.
시스템 구성도
프로그램은 크게 세 가지로 이루어진다. 리액트를 이용한 웹 페이지와 장고를 이용한 웹 서버와 머신러닝, 딥러닝 API를 이용한 학습 및 예측으로 구성되어 있다. 이 세 가지가 서로 동작하는 방법은 위 그림과 같이 이루어진다.
전 세계 사망 원인 2위, 한국인 사망 원인 4위인 뇌졸중은 국내에서만 연간 60만 명에 달하는 환자들이 발생하고 있다. 현대인들의 식습관, 흡연, 운동 부족 등의 이유로 인하여 어느 날 갑자기 뇌졸중이 찾아올 수 있기 때문에 일반인은 미리 대비하는 것이 쉽지 않다. 뇌졸중이 발생한 후 적절한 응급 치료를 빠른 시간 내에 받지 못한다면 근력마비, 보행장애, 언어장애, 감각장애등의 후유증이 생길 수 있고 최악의 경우에는 사망할 수 있다. 따라서 골든타임인 발병 후 6시간에서 최대 10시간 이내에 병원을 찾아 치료받는 것이 중요하다.
뇌졸중이 발병되었음을 인지할 수 있는 초기 증상들로는 말할 때 발음의 어눌함, 심한 두통, 얼굴이 부분적으로 마비되는 등 여러 종류가 있을 수 있다. 이들 중 안면 마비 증상이 제3자가 보았을 때 환자가 발생했음을 인지하기 제일 쉬운 방법이다. 뇌졸중이 발병한 환자들은 일반적으로 얼굴 한쪽이 마비되어서 심한 비대칭성을 나타내기 때문이다. 그러나 뇌졸중을 경험하고 있는 환자들은 감각에 대한 둔화가 오는 증상들이 동반되기 쉬워 거울을 보았을 때 스스로 얼굴에 이상이 있음을 인지하기 쉽지가 않다.
그래서 ‘건강한 얼굴 건강한 정신’이라는 프로그램을 기획하게 되었다. 이 프로그램은 주위에 제3자가 없더라도 핸드폰이나 노트북 등으로 손쉽게 뇌졸중의 초기 증상인 안면 마비 증상을 인지할 수 있도록 도움을 준다. 1인 가구 또는 혼자 보내는 시간이 많은 이들에게 자신이 뇌졸중을 경험하고 있는지 판단할 수 있도록 자가 진단을 제공하는 것이 이 프로그램의 목적이다.
총 N개의 시험장이 있고, 각각의 시험장마다 응시자들이 있다. i번 시험장에 있는 응시자의 수는 Ai명이다.
감독관은 총감독관과 부감독관으로 두 종류가 있다. 총감독관은 한 시험장에서 감시할 수 있는 응시자의 수가 B명이고, 부감독관은 한 시험장에서 감시할 수 있는 응시자의 수가 C명이다.
각각의 시험장에 총감독관은 오직 1명만 있어야 하고, 부감독관은 여러 명 있어도 된다.
각 시험장마다 응시생들을 모두 감시해야 한다. 이때, 필요한 감독관 수의 최솟값을 구하는 프로그램을 작성하시오.
풀이
이 문제는 굉장히 간단한 문제이다. 입력은 다음과 같이 주어진다.
첫째 줄에 시험장의 개수 N(1 ≤ N ≤ 1,000,000)이 주어진다.
둘째 줄에는 각 시험장에 있는 응시자의 수 Ai (1 ≤ Ai ≤ 1,000,000)가 주어진다.
셋째 줄에는 B와 C가 주어진다. (1 ≤ B, C ≤ 1,000,000)
만약 시험장이 1,000,000개이고 응시자 수가 1,000,000에 B, C가 각각 1인 경우 최대로 필요한 감독관의 수는 10^12이 된다. 약 2*10^9까지 표현할 수 있는 int형으로는 부족하다. 따라서 64비트를 이용하는 long long형을 사용해야한다. 풀이는 너무 간단하다. 각 시험장의 응시자의 수에서 B를 빼고 남은 인원이 0보다 클 경우 a에 C-1을 더하고 C로 나눈 몫만큼의 부감독관이 필요하다. 자세히 설명하자면 아래와 같다.
만약 응시자 수에서 B를 뺀 값이 4라고 하자.
C의 값이 5라고 하면 1명의 부감독관만 필요하다.
4에 C-1인 4를 더하면 8이므로 5로 나눈 몫은 1이다.
만약 5명이 남았다고한다면 5에 C-1인 4를 더하면 9이고 이를 5로 나눈 몫은 그대로 1이다.
즉 나누려고하는 값에서 1을 뺀 값을 나눠지는 수에 더하고 나누면 소수점에서 올림을 할 수 있다.
소스 코드
#include <iostream>
#include <cstring>
#include <vector>
#include <deque>
using namespace std;
vector<int> arr;
int main() {
int N; cin >> N;
long long answer = 0; //정답
for(int i = 0; i < N; i++) {
int a; cin >> a;
arr.push_back(a);
}
int B, C; cin >> B >> C;
for(int a : arr) {
a -= B; //총감독관이 감시할 수 있는 인원 빼기
if(a > 0){ //그래도 수험생이 남아있으면
a += (long long)(C-1); //C-1을 더함
answer += (long long)(a / C); //C로 나눈 몫을 정답에 더하기
}
answer++; //총감독관 인원 더하기
}
cout << answer;
}
B를 뺀 값이 0보다 클 때 즉 수험생이 남아있는지 확인하는 이유는 만약 B를 뺀 값이 -5이고 C의 값이 4라고 한다면 C-1을 더하더라도 음수가 된다. 따라서 이상한 값이 나올 수 있기 때문이다.
이 문제는 정답 비율에 비해 쉽게 구현할 수 있는 문제이다. 문제는 간단하다. 뱀이 이동하며 사과를 먹으면 몸의 길이가 늘어난다. 문제에 설명이 부족하여 헷갈렸지만 1초에 1칸씩 움직인다고 생각하면 된다.
풀이
이 문제는 방향성을 가지고 있는 문제이다. 현재 진행 방향에서 좌회전하냐 우회전하냐의 문제를 쉽게 구현하기 위하여 아래와 같이 방향을 나타내는 배열을 이용하였다. dx, dy의 인덱스 값을 1 올릴 때마다 시계 방향으로 회전하고 반대로 1 내릴 때마다 반시계 방향으로 회전한다.
int dx[4] = {-1, 0, 1, 0}; //상, 우, 하, 좌 : 시계방향
int dy[4] = {0, 1, 0, -1};
뱀을 나타내기 위하여 앞 뒤로 좌표를 넣어야한다는 점에 딱 맞은 deque를 이용해야겠다고 생각했다. deque의 front는 뱀의 머리를, back은 뱀의 꼬리를 나타낸다. NxN 보드에서 1인 점은 사과가 있는 지점이고 -1인 곳은 뱀이 차지하고 있는 곳이다. 알고리즘은 다음과 같이 동작한다.
만약 머리가 향하는 다음 지점이 보드를 벗어날 경우 게임이 끝난지를 판단하는 fin변수를 true로 바꾸고 게임을 종료한다.
뱀을 나타내는 deque에 다음 지점의 좌표를 push_front하여 머리를 갱신해준다.
그렇지 않은 경우 만약 머리가 향하는 다음 지점에 사과가 없을 경우 꼬리부분을 pop_back하고 -1이었던 꼬리부분을 0으로 바꾸어준다.
그 다음 머리가 향한 다음 지점이 -1인 경우, 즉 뱀의 몸통을 만난 경우 fin변수를 true로 바꾸고 게임을 종료한다.
뱀의 머리가 향하는 다음 지점을 -1로 바꾼다.
왼쪽으로 회전하는 경우 방향을 나타내는 변수에 3을 더하고 4로 나눈 나머지를 다음 방향으로 정한다.
오른쪽으로 회전하는 경우 방향을 나타내는 변수에 1을 더하고 4로 나눈 나머지를 다음 방향으로 정한다.
방향을 모두 바꾼 다음에도 종료되지 않은 경우 벽을 만날 때까지 직진한다.
소스 코드
#include <iostream>
#include <cstring>
#include <vector>
#include <deque>
using namespace std;
int arr[101][101]; //보드 배열
int N, K, L;
int dx[4] = {-1, 0, 1, 0}; //상, 우, 하, 좌 : 시계방향
int dy[4] = {0, 1, 0, -1};
deque<pair<int,int>> snake; //뱀을 나타내는 deque
vector<pair<int,char>> info; //이동 시간과 위치 저장 벡터
int main() {
bool fin = false; //게임이 끝난지 판단하는 변수
int direction = 1; //현재 방향(오른쪽)
int answer = 0; //정답
int time = 0; //시간
snake.push_front({1, 1}); //현재 위치 뱀에 추가
arr[1][1] = -1; //뱀이 현재 있는 곳 표시
cin >> N >> K; //입력
for(int i = 0; i < K; i++) {
int a, b; cin >> a >> b;
arr[a][b] = 1;
}
cin >> L;
for(int i = 0; i < L; i++) {
int x; char c; cin >> x >> c;
info.push_back({x - time, c});
time = x;
}
for(pair<int, char> e : info) {
int x = e.first; //시간
char c = e.second; //다음 방향
while(!fin && x--) {
answer++; //시간 증가
int nx = snake.front().first + dx[direction]; //다음 x, y 좌표
int ny = snake.front().second + dy[direction];
if(nx < 1 || nx > N || ny < 1 || ny > N) { //벽에 닿은 경우 종료
fin = true;
break;
}
snake.push_front({nx, ny}); //뱀의 머리 갱신
if(arr[nx][ny] == 0) { //사과가 없는 경우
pair<int,int> back = snake.back(); //꼬리 제거
snake.pop_back();
arr[back.first][back.second] = 0; //보드에서 삭제
}
if(arr[nx][ny] == -1) { //뱀의 몸통을 만난 경우
fin = true; //게임 종료
break;
}
arr[nx][ny] = -1; //뱀의 머리 보드에 체크
}
if(c == 'L') //왼쪽으로 회전하는 경우
direction += 3;
else //오른쪽으로 회전하는 경우
direction++;
direction %= 4; //4개의 원소가 있으므로 범위를 벗어나지 않고 회전하게 만듦
}
while(!fin) { //방향 조절이 끝난 후 벽에 부딪힐 때까지 직진
answer++;
int nx = snake.front().first + dx[direction]; //다음 x, y 좌표
int ny = snake.front().second + dy[direction];
if(nx < 1 || nx > N || ny < 1 || ny > N) { //벽에 부딪힌 경우 종료
fin = true;
break;
}
snake.push_front({nx, ny}); //머리 갱신
if(arr[nx][ny] == 0) { //사과가 없는 경우
pair<int,int> back = snake.back(); //꼬리 제거
snake.pop_back();
arr[back.first][back.second] = 0;
}
if(arr[nx][ny] == -1) { //몸통을 만난 경우 종료
fin = true;
break;
}
arr[nx][ny] = -1; //뱀이 있으므로 체크
}
cout << answer; //정답 출력
}
이번 글에는 STL의 <queue> 헤더파일에 존재하는 내부 함수 우선순위 큐를 직접 구현해보았다. priority_queue를 C++ STL 홈페이지(https://www.cplusplus.com/reference/queue/priority_queue/?kw=priority_queue)에서 찾아볼 경우 다음과 같이 나온다.
초록색 글씨를 보면 선언할 때 변수의 type(class도 가능)을 받고 두 번째 인자로 우선순위 큐를 구성하는 컨테이너, 즉 배열을 선언할 수 있다. 기본값으론 vector를 사용한다. 마지막 인자로 힙을 구성하는 비교 함수 연산자가 있는 class를 포함한다. 기본값인 less는 최대힙을 만들 때 사용한다. 최소힙으로 사용하고 싶을 경우 greater를 사용한다. 다음과 같이 최대힙, 최소힙을 선언할 수 있다.
우선순위 큐는 힙을 이용한다. FIRST IN FIRST OUT인 queue와 다르게 우선순위가 높은 인자가 우선적으로 나온다. 힙의 push와 pop은 다음과 같이 동작한다. 예시는 5, 6, 3, 7, 10, 4가 순서대로 push될 경우 최대힙이 만들어지는 과정이다.
힙은 언제나 완전 이진트리이다. 동작방식은 다음과 같다.
삽입
삽입하려는 값을 트리의 맨 마지막에 넣는다.
부모노드와 비교하며 삽입하려는 값이 더 큰 경우 부모노드와 값을 바꾼다.
삽입하려는 값보다 큰 값이 나오지 않을 때까지 반복한다.
만약 root노드보다 삽입하려는 값이 큰 경우 root노드에 저장한다.
삭제
트리의 맨 아래의 맨 오른쪽에 있는 원소인 pivot을 root노드로 위치시킨다.
왼쪽 자식 노드와 오른쪽 자식 노드 중 큰 값과 비교한다.
자식 노드가 더 큰 경우 자식노드와 값을 바꾼다.
pivot 값보다 작은 값을 만날 때까지 반복한다.
만약 leaf노드까지 도달한 경우 pivot 값을 leaf노드에 저장한다.
우선순위 큐는 위의 과정으로 동작한다. 여기서 비교하는 함수는 선언의 마지막 인자에 있는 class를 이용하여 비교연산을 한다.
priority_queue 코드 설명
class의 구조와 멤버 변수는 다음과 같다.
template <class T, class CONT = std::vector<T>, class CMP = less<typename CONT::value_type>>
class mypriority_queue {
private:
CONT container;
int num;
CMP compare;
}
맨 첫 번째 줄을 보면 글 맨 위에 있는 사진에서 확인할 수 있듯이 template를 동일하게 선언하였다. 타입, 컨테이터, 비교클래스.
멤버변수는 template로 선언한 container가 컨테이너, num은 원소의 수를 나타내고 compare는 비교를 실행할 인스턴스이다. 비교 클래스를 받기 때문에 클래스 안에 있는 비교함수나 연산자를 이용하기 위해선 그 class를 타입으로 가지는 인스턴스가 존재해야하기 때문에 선언하였다. 예를 들어 CMP안에 ()연산자가 정의된 경우 compare(a, b)와 같이 사용하여 비교연산을 수행할 수 있다.
사이트에 나와있는 멤버 함수는 다음과 같다.
이 중에 구현한 함수는 생성자를 포함해 empty, size, top, push, pop을 구현하였다. 다른 함수들은 많이 사용되지 않기 때문에 생략하였다.
처음 문제를 O(N)만에 풀 수 있는 방법을 생각해보았지만 뜻대로 되지 않고 자꾸 DFS를 이용하는 방법이 떠올라 DFS를 이용하지 않고 풀어보려했지만 결국 DFS를 사용하게 되었다. 이 문제가 까다로운 부분은 원형으로 연결되어 있다는 것이다. 1차원 배열의 맨 끝에서 오른쪽으로 한 번 더 이동하면 첫 번째 원소에 와야하는 것과 같은 예외처리를 해야한다. 문제는 다음과 같이 풀었다.
DFS를 이용하여 임의의 취약지점에서 출발한다.
점검할 수 있는 취약지점까지 점검한다.
다음 취약지점부터 아직 점검하지 않은 친구가 점검할 수 있는 거리만큼 점검한다.
만약 점검한 취약지점 수와 전체 취약지점 수가 같은 경우 결과값을 최소값으로 갱신한다.
소스 코드
#include <string>
#include <vector>
#include <iostream>
#include <algorithm>
using namespace std;
int answer = 1e9; //정답 최대값으로 설정
int N;
vector<bool> dvisit; //점검을 완료한 친구 표시
void dfs(int ans, int now, int len, int total, vector<int> &weak, vector<int> &dist) {
int start = weak[now]; //시작 취약지점
int limit = weak[now] + dist[len]; //점검할 수 있는 거리의 마지노선
int cnt = 0; //점검한 취약지점 수
if(limit >= N) { //만약 범위를 벗어나 다시 0부터 시작하는 경우
while(true) {
if((weak[now] >= start) || (weak[now] <= (limit % N))) { //다음 탐색할 취약지점이 점검할 수 있는 범위에 있는 경우
now++; //다음 취약지점으로 이동
now %= weak.size(); //범위 벗어나지 않게 처리
cnt++; //점검한 취약지점 수 증가
if(cnt + total == weak.size()) { //취약지점 모두 점검한 경우
answer = min(answer,ans); //최소값 갱신
return; //리턴
}
}
else { //범위를 벗어난 경우 점검 종료
break;
}
}
}
else { //만약 범위를 벗어나지 않는 경우
while(true) {
if((weak[now] >= start) && (weak[now] <= limit)) { //다음 탐색할 취약지점이 점검할 수 있는 범위에 있는 경우
now++; //다음 취약지점으로 이동
now %= weak.size(); //범위 벗어나지 않게 처리
cnt++; //점검한 취약지점 수 증가
if(cnt + total == weak.size()) { //취약지점 모두 점검한 경우
answer = min(answer,ans); //최소값 갱신
return; //리턴
}
}
else { //범위를 벗어난 경우 점검 종료
break;
}
}
}
for(int d = 0; d < dist.size(); d++) { //점검할 다음 친구 선택
if(dvisit[d]) continue; //이미 점검한 친구는 패스
dvisit[d] = true; //방문표시
dfs(ans+1 , now, d, total + cnt, weak, dist); //DFS를 이용하여 now부터 취약지점 점검
dvisit[d] = false; //방문표시 취서
}
}
int solution(int n, vector<int> weak, vector<int> dist) {
N = n; //외벽길이 전역변수로 저장
dvisit.resize(dist.size()); //방문배열 크기 설정
sort(dist.begin(), dist.end(), greater<int>()); //큰 것부터 정렬
for(int w = 0; w < weak.size(); w++) { //점검을 시작할 취약지점 위치
for(int d = 0; d < dist.size(); d++) { //점검할 친구 선택
dvisit[d] = true;
dfs(1, w, d, 0, weak, dist);
dvisit[d] = false;
}
}
if(answer == 1e9) return -1; //모두 탐색하지 못한 경우 -1 리턴
else return answer; //그렇지 않은 경우 최소값 리턴
}
최대한 반복되는 비교를 하지 않도록 방문함수를 설정하고 점검한 취약지점을 다시 점검하도록 하지 않도록 다음 취약지점으로 이동하며 점검하도록 프로그램을 짜보았다. DFS함수의 인자가 많은 것이 아쉬운 부분이지만 다른 방법으로는 떠오르지 않아 함수의 인자 밖에 선택할 수 없었다. weak와 dist를 모두 전역변수로 하면 메모리 낭비와 복사하는 시간이 걸리므로 call by reference를 이용하여 그런 시간을 줄여보았다.