https://programmers.co.kr/learn/courses/30/lessons/76503
코딩테스트 연습 - 모두 0으로 만들기
각 점에 가중치가 부여된 트리가 주어집니다. 당신은 다음 연산을 통하여, 이 트리의 모든 점들의 가중치를 0으로 만들고자 합니다. 임의의 연결된 두 점을 골라서 한쪽은 1 증가시키고, 다른 한
programmers.co.kr
문제 설명
각 점에 가중치가 부여된 트리가 주어집니다. 당신은 다음 연산을 통하여, 이 트리의 모든 점들의 가중치를 0으로 만들고자 합니다.
- 임의의 연결된 두 점을 골라서 한쪽은 1 증가시키고, 다른 한쪽은 1 감소시킵니다.
하지만, 모든 트리가 위의 행동을 통하여 모든 점들의 가중치를 0으로 만들 수 있는 것은 아닙니다. 당신은 주어진 트리에 대해서 해당 사항이 가능한지 판별하고, 만약 가능하다면 최소한의 행동을 통하여 모든 점들의 가중치를 0으로 만들고자 합니다.
트리의 각 점의 가중치를 의미하는 1차원 정수 배열 a와 트리의 간선 정보를 의미하는 edges가 매개변수로 주어집니다. 주어진 행동을 통해 트리의 모든 점들의 가중치를 0으로 만드는 것이 불가능하다면 -1을, 가능하다면 최소 몇 번만에 가능한지를 찾아 return 하도록 solution 함수를 완성해주세요. (만약 처음부터 트리의 모든 정점의 가중치가 0이라면, 0을 return 해야 합니다.)
문제 예시

위의 그림처럼 모든 하나의 노드는 증가, 하나의 노드는 감소시키면서 모든 노드의 가중치를 0으로 만들 경우 증가나 감소시키는 횟수를 리턴하면 된다.
문제 풀이
위 예시에서 보았듯이 이 문제는 리프노드 즉 가장 끝에 있는 노드부터 순서대로 0으로 만들어가다보면 풀리는 문제이다. 따라서 깊이우선 탐색을 하며 자식 노드부터 순서대로 0으로 만들어가면 문제를 풀 수 있다. 그렇다면 자식 노드부터 0으로 만들기 위해선 코드상에서 어떻게 해야할까?
#include <string>
#include <vector>
#include <iostream>
#include <cmath>
using namespace std;
vector<long long> weight; //각 노드의 현재 가중치 저장
vector<int> g[300001]; //인접리스트를 이용한 그래프 표현
bool visit[300001]; //방문여부 표시
long long answer;
void dfs(int now) {
visit[now] = true; //현재 노드 방문 체크
for(int child : g[now]) { //자식 노드를 돌며
if(visit[child]) continue; //방문노드(부모노드)는 스킵
dfs(child); //자식노드를 먼저 탐색하고
answer += abs(weight[child]); //증가/감소하는 횟수 더하기
weight[now] += weight[child]; //부모노드의 가중치 증가/감소
weight[child] = 0; //자식노드 0으로 만들기
}
}
long long solution(vector<int> a, vector<vector<int>> edges) {
for(int e : a) {
weight.push_back((long long)e); //long long형으로 가중치 배열 다시 만들기
}
for(vector<int> e : edges) { //인접리스트 그래프 만들기
g[e[0]].push_back(e[1]);
g[e[1]].push_back(e[0]);
}
dfs(0); //dfs탐색
if(weight[0] != 0) return -1; //모두 0으로 만들지 못한 경우 -1리턴
else return answer; //그렇지 않은 경우 정답 리턴
}이 코드와 같이 자식노드를 먼저 탐색한 다음 부모노드의 가중치를 수정하면 된다. 위 코드의 19~22번줄과 같이 dfs(child)로 자식노드를 먼저 탐색하고서 부모노드의 가중치를 수정하고 자식노드를 0으로 만드는 것을 알 수 있다. 현재 노드의 자식노드가 있을 때 그 자식노드가 리프노드가 아닐 경우 리프노드부터 차례대로 0으로 만들어 올라오며 수정된 가중치를 가지고 현재 노드를 수정해야하기 때문이다. 이렇게 가중치를 계산하는 부분의 위치만 잘 생각하면 쉽게 풀 수 있는 문제였다.
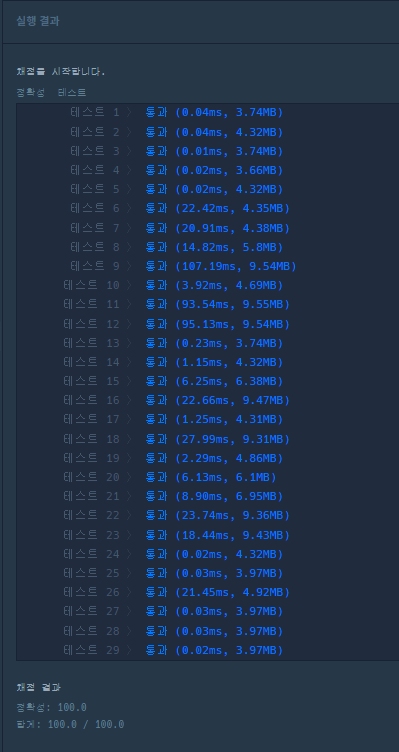
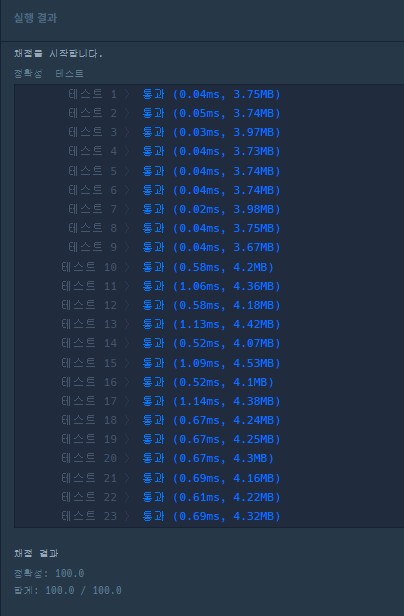
채점 결과

'알고리즘 > 프로그래머스' 카테고리의 다른 글
| [C++] 프로그래머스 순위 검색 풀이 (0) | 2021.08.06 |
|---|---|
| [C++] 프로그래머스 110 옮기기 풀이 (0) | 2021.08.06 |
| [C++] 프로그래머스 길 찾기 게임 풀이 (0) | 2021.08.03 |
| [C++] 프로그래머스 기둥과 보 설치 풀이 (0) | 2021.08.03 |
| [C++] 프로그래머스 광고 삽입 풀이 (0) | 2021.08.01 |