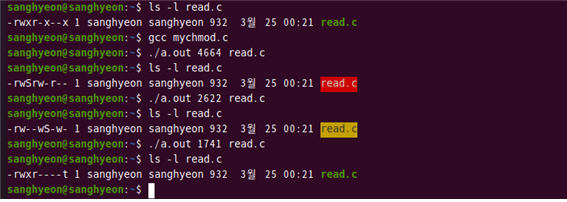
이 글에서는 짧은 bash shell script 프로그램을 작성하여 실행해보도록 하겠다.
이 프로그램은 두 정수를 입력받아 두 정수 사이에 속하는 모든 소수의 합을 구하는 프로그램이다. 코드는 다음과 같다.
#!/bin/bash
let rst=0
echo -n "type two integers : "
read x y
if [ $x == $y ] #만약 두 숫자가 같다면 x, y사이에 값이 없으므로 0을 출력하고 종료
then
echo 0
exit 1
fi
if [ $x -gt $y ] //x보다 y가 작다면 둘이 숫자를 swap
then
let tmp=$x
x=$y
y=$tmp
fi
let x++
while (( $x != $y )) #x가 y보다 작을 때까지
do
if [ $x -eq 2 ] #2인 경우 추가
then
let rst+=2
let x++
continue;
fi
tmp=2 #나누는 수 2부터 시작
until (( $tmp == $x )) #나누는 수가 x보다 작을 동안만 반복
do
let rest=$x%$tmp #나머지 계산
if [ $rest -eq 0 ] #나누어 떨어지는 경우
then
break;
fi
let tmp++ #나누어 떨어지지 않는 경우
done
if [ $tmp -eq $x ] #2부터 x-1까지 x와 나누어 떨어지는 수가 하나도 없는 경우
then
let rst+=$x #rst에 x 더함
fi
let x++ #x 1 증가
done
echo "result : $rst"
이 코드는 다음과 같이 실행된다.
1. x와 y가 같은지 확인한다. 같을 경우 0출력하고 종료
2. y가 x보다 큰지 확인한다. 그럴 경우 두 변수를 바꾼다.
3. x를 1씩 증가하며 y보다 작을 때까지 계산을 반복한다.
3-1. x가 2인경우 rst에 x를 더한다.
3-2. x가 소수인지 판별할 tmp변수를 2부터 x-1까지 1씩 증가하며 x와 나누어 떨어지는지 확인한다.
3-3. 만약 나누어 떨어지는 수가 있는 경우 rst에 아무것도 더하지 않고 x를 1 증가시킨다.
3-4. 만약 2부터 x-1까지 모든 수가 x와 나누어 떨어지지 않는 경우 rst에 x를 더한다.
위 실행 결과는 wsl2 ubuntu-20.04버전에서 실행한 결과이다.
'리눅스 시스템 프로그래밍' 카테고리의 다른 글
| [Linux] 리눅스 시스템 프로그래밍 thread(스레드) 생성과 종료 (0) | 2021.08.06 |
|---|---|
| [Linux] 저수준 파일 입출력과 고수준 파일 입출력 (0) | 2021.07.20 |
| [Linux] Bash shell script programming 2021년도 요일 구하기 (0) | 2021.07.19 |
| [Linux] Bash shell 환경 변수와 지역 변수 (0) | 2021.07.19 |
| [Linux] 리눅스시스템프로그래밍 ls, chmod, touch 명령어 만들기 (0) | 2021.07.09 |