https://programmers.co.kr/learn/courses/30/lessons/60061
코딩테스트 연습 - 기둥과 보 설치
5 [[1,0,0,1],[1,1,1,1],[2,1,0,1],[2,2,1,1],[5,0,0,1],[5,1,0,1],[4,2,1,1],[3,2,1,1]] [[1,0,0],[1,1,1],[2,1,0],[2,2,1],[3,2,1],[4,2,1],[5,0,0],[5,1,0]] 5 [[0,0,0,1],[2,0,0,1],[4,0,0,1],[0,1,1,1],[1,1,1,1],[2,1,1,1],[3,1,1,1],[2,0,0,0],[1,1,1,0],[2,2,0,1]] [[
programmers.co.kr
문제 설명
이 문제는 접근 방법이 까다로웠던 문제이다. 문제의 조건은 다음과 같다.
- 기둥은 바닥 위에 있거나 보의 한쪽 끝 부분 위에 있거나, 또는 다른 기둥 위에 있어야 합니다.
- 보는 한쪽 끝 부분이 기둥 위에 있거나, 또는 양쪽 끝 부분이 다른 보와 동시에 연결되어 있어야 합니다.
문제의 입력으로 벽면의 크기 n과 기둥과 보를 설치하거나 삭제하는 작업이 순서대로 담긴 2차원 배열 build_frame이 주어진다. build_frame의 원소는 다음과 같다.
- build_frame의 원소는 [x, y, a, b]형태입니다.
- x, y는 기둥, 보를 설치 또는 삭제할 교차점의 좌표이며, [가로 좌표, 세로 좌표] 형태입니다.
- a는 설치 또는 삭제할 구조물의 종류를 나타내며, 0은 기둥, 1은 보를 나타냅니다.
- b는 구조물을 설치할 지, 혹은 삭제할 지를 나타내며 0은 삭제, 1은 설치를 나타냅니다.
- 벽면을 벗어나게 기둥, 보를 설치하는 경우는 없습니다.
- 바닥에 보를 설치 하는 경우는 없습니다.
- 구조물은 교차점 좌표를 기준으로 보는 오른쪽, 기둥은 위쪽 방향으로 설치 또는 삭제합니다.

위 그림에 대한 입력의 예시는 다음과 같다.

풀이
코드는 다음과 같다.
#include <string>
#include <vector>
#include <algorithm>
using namespace std;
bool graph[4][101][101]; //좌표의 상하좌우 표시
bool ans(vector<int> a, vector<int> b) { //결과 정렬 비교함수
if(a[0] == b[0]) {
if(a[1] == b[1]) {
return a[2] < b[2];
}
else {
return a[1] < b[1];
}
}
else {
return a[0] < b[0];
}
}
vector<vector<int>> solution(int n, vector<vector<int>> build_frame) {
vector<vector<int>> answer;
for(vector<int> element : build_frame) {
int x = element[0], y = element[1];
int construct = element[2], install = element[3];
if(install) { //설치인 경우
if(construct == 0) { //기둥인 경우
if(y == 0) { //바닥인 경우 그냥 설치
graph[0][x][y] = 1;
graph[1][x][y+1] = 1;
}
else { //바닥이 아닌 경우
if(graph[1][x][y] || graph[2][x][y] || graph[3][x][y]) { //보의 끝이거나 기둥 위에 올릴 수 있음
graph[0][x][y] = 1;
graph[1][x][y+1] = 1;
}
}
}
else { //보인 경우
if(graph[1][x][y] || graph[1][x+1][y]) { //한쪽 끝이 기둥 윗부분인 경우
graph[3][x][y] = 1;
graph[2][x+1][y] = 1;
}
else if(graph[2][x][y] && graph[3][x+1][y]) { //양쪽 끝이 보인 경우
graph[3][x][y] = 1;
graph[2][x+1][y] = 1;
}
}
}
else { //제거인 경우
if(construct == 0) { //기둥을 삭제할 경우
bool chk = 0;
if(graph[0][x][y+1]) { //위에 기둥이 있는 경우
if(!(graph[2][x][y+1] || graph[3][x][y+1])) chk = 1; //보가 있으면 삭제 가능
}
if(graph[2][x][y+1]) { //왼쪽으로 보가 있는 경우
if(!(graph[2][x-1][y+1] && graph[3][x][y+1]) && !graph[1][x-1][y+1]) chk = 1; //양쪽에 보가 있으면 삭제 가능
}
if(graph[3][x][y+1]) { //오른쪽으로 보가 있는 경우
if(!(graph[2][x][y+1] && graph[3][x+1][y+1]) && !graph[1][x+1][y+1]) chk = 1; //양쪽에 보가 있으면 삭제 가능
}
if(!chk) {
graph[0][x][y] = 0;
graph[1][x][y+1] = 0;
}
}
else { //보를 삭제하는 경우
bool chk = 0;
if(graph[0][x][y]) { //위에 기둥이 있는 경우
if(!(graph[2][x][y] || graph[1][x][y])) chk = 1; //왼쪽으로 보도 없고 아래에 기둥도 없는 경우 삭제 불가
}
if(graph[0][x+1][y]) { //위에 기둥이 있는 경우
if(!(graph[3][x+1][y] || graph[1][x+1][y])) chk = 1;
}
if(graph[2][x][y]) { //왼쪽에 보가 있는 경우
if(!(graph[1][x][y] || graph[1][x-1][y])) chk = 1; //왼쪽 보가 기댈 기둥이 하나도 없는 경우 삭제 불가
}
if(graph[3][x+1][y]) { //오른쪽에 보가 있는 경우
if(!(graph[1][x+1][y] || graph[1][x+2][y])) chk = 1;
}
if(!chk) {
graph[3][x][y] = 0;
graph[2][x+1][y] = 0;
}
}
}
}
for(int i = 0; i <= n; i++) {
for(int j = 0; j <= n; j++) {
if(graph[0][i][j]) answer.push_back({i, j, 0}); //기둥 구조물 저장
if(graph[3][i][j]) answer.push_back({i, j, 1}); //보 구조물 저장
}
}
sort(answer.begin(), answer.end(), ans); //결과 정렬
return answer;
}우선 마지막 조건을 보고 좌표에 시작점만을 표시한다면 문제를 풀기 굉장히 어려워진다. 따라서 3차원 배열을 이용하여 각 좌표에 상하좌우에 구조물이 있는지를 표시하였다. 그림으로 나타내면 다음과 같다.

예를 들어 (x,y)에 오른쪽과 아래로 구조물이 존재한다면 x,y 좌표의 오른쪽과 아래쪽에 해당하는 값만 1이다. 즉 다음과 같다.
graph[0][x][y] = 0; //상
graph[1][x][y] = 1; //하
graph[2][x][y] = 0; //좌
graph[3][x][y] = 1; //우이렇게 한다면 구조물의 시작부분뿐만 아니라 끝부분도 표시할 수 있다. 1과 0의 값만 사용하기 때문에 메모리 절약을 위해 bool 타입으로 선언하였다. 설치하고 제거하는 조건은 문제에 나와있는 경우의 수를 생각해보았다.
1. 기둥을 설치하는 경우
- 만약 바닥인 경우 아무 조건 없이 설치
- 보의 끝이거나 기둥의 위인 경우 설치
2. 보를 설치하는 경우
- 한쪽 끝이 기둥 윗부분인 경우 설치
- 양쪽 끝이 보인 경우 설치
제거하는 경우는 모든 조건이 만족할 경우 제거를 할 수 있다. 따라서 제거하지 못할 조건을 체크하였다.
3. 기둥을 제거하는 경우
- 위에 기둥이 있을 경우
- 왼쪽 오른쪽에 보가 하나도 없을 경우 제거 불가
- 왼쪽에 보가 있을 경우
- 보의 왼쪽 오른쪽 모두 보가 존재하지 않을 경우 제거 불가
- 보를 지탱하는 기둥이 하나도 없을 경우 제거 불가
- 오른쪽에 보가 있을 경우
- 보의 왼쪽 오른쪽 모두 보가 존재하지 않을 경우 제거 불가
- 보를 지탱하는 기둥이 하나도 없을 경우 제거 불가
위 조건을 모두 만족할 경우 제거 가능
4. 보를 제거하는 경우
- 바로 위에 기둥이 있는 경우
- 왼쪽에 보가 없고 아래에 기둥도 없는 경우 제거 불가
- 제거하려는 보의 다른쪽 끝 위에 기둥이 있는 경우
- 그 기둥을 지탱하는 보나 기둥이 없는 경우 제거 불가
- 왼쪽에 보가 있는 경우(한쪽이 연결된 보가 제거되므로 기둥만 생각하면 됨)
- 보가 지탱할 기둥이 하나도 없는 경우 제거 불가
- 오른쪽에 보가 있는 경우
- 보가 지탱할 기둥이 하나도 없는 경우 제거 불가
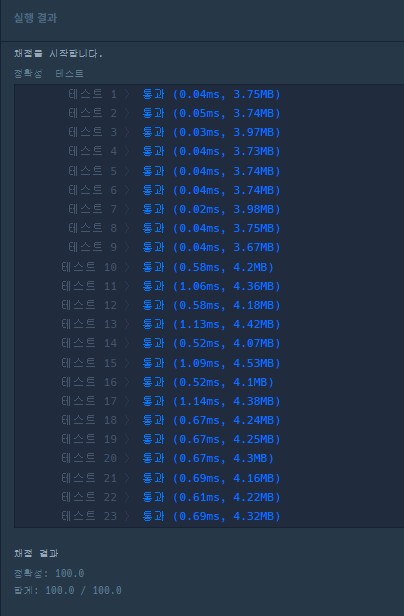
위의 규칙에 따라 기둥을 하나씩 설치하고 제거한 다음 구조물이 그래프에 완성된다. 구조물의 결과를 리턴해야하므로 각 좌표를 하나씩 순회하며 기둥은 위로, 보는 오른쪽으로 설치하므로 graph의 1차원 인덱스가 0이나 3일 경우 값이 참일 때 정답 벡터에 좌표와 기둥인지 보인지를 push_back해준다. 모두 넣은 다음 answer를 조건에 따라 정렬하여 리턴하면 된다. 위 코드를 실행할 경우 다음과 같이 모두 통과하는 것을 볼 수 있다.
'알고리즘 > 프로그래머스' 카테고리의 다른 글
| [C++] 프로그래머스 모두 0으로 만들기 풀이 (3) | 2021.08.05 |
|---|---|
| [C++] 프로그래머스 길 찾기 게임 풀이 (0) | 2021.08.03 |
| [C++] 프로그래머스 광고 삽입 풀이 (0) | 2021.08.01 |
| [C++] 프로그래머스 징검다리 건너기 풀이 (0) | 2021.07.31 |
| [C++] 프로그래머스 합승 택시 요금 (0) | 2021.07.30 |