https://programmers.co.kr/learn/courses/30/lessons/42893
코딩테스트 연습 - 매칭 점수
매칭 점수 프렌즈 대학교 조교였던 제이지는 허드렛일만 시키는 네오 학과장님의 마수에서 벗어나, 카카오에 입사하게 되었다. 평소에 관심있어하던 검색에 마침 결원이 발생하여, 검색개발팀
programmers.co.kr
문제 풀이
이 문제는 카카오답게 문자열을 다루는 스킬을 확인하는 문제인 것 같다. 이 문제에서 찾아야할 문자열은 url, 검색하고자 하는 단어, 링크가 걸린 url을 찾아야한다. 각각 다음과 같은 방식으로 찾는다.
1. url 검색 : url이 담긴 문자열은 다음과 같이 시작한다.
<meta property="og:url" content="https://
이 문자열로 시작하는 부분을 찾아 content="________"에 밑줄에 해당하는 부분을 저장한다.
2. 검색하고자 하는 단어 : 대문자로 한 번, 소문자로 한 번 찾는다.
대문자로 문자를 바꿔주는 toupper()와 소문자로 문자를 바꿔주는 tolower를 이용해 word의 첫 문자를 대문자, 소문자로 찾아 일치하는 단어가 있는지 비교한다. 비교는 모든 문자열을 대문자로 바꿔 비교한다.
3. 링크가 걸린 url : 링크 주소 문자열은 다음과 같이 시작한다.
<a href=\"https://
이 문자열로 시작하는 부분을 전부 찾아 자신을 가리키는 페이지의 인덱스를 저장하는 배열에 넣어주고 현재 페이지에서 가리키는 링크의 수를 증가시킨다.
위의 과정대로 짠 코드이다.
소스 코드
#include <string>
#include <iostream>
#include <vector>
#include <map>
#include <set>
using namespace std;
string url[21]; //index - url 매핑
double basic[21]; //기본점수
int linknum[21]; //각 노드의 외부링크
map<string, set<int>> links; //자기를 가리키는 링크 저장
bool isSame(string &a, string &b) { //문자열 비교 함수
for(int i = 0; i < a.length(); i++) {
if(!isalpha(b[i])) { // 알파벳이 아니면 false 리턴
return false;
break;
}
if(toupper(a[i]) != toupper(b[i])) { //같지 않으면 false 리턴
return false;
break;
}
}
return true;
}
int solution(string word, vector<string> pages) {
int answer = 0;
double mnum = 0;
for(int i = 0; i < pages.size(); i++) {
string &now = pages[i];
//url찾기
int start = now.find("<meta property=\"og:url\" content=\"https://"); //url이 담긴 문자열 검색
start += 33; //url 시작 주소로 이동
int end = now.find("\"", start); //"로 끝나는 위치 저장
string nowurl = now.substr(start, end - start); //url 저장
url[i] = nowurl;
start = now.find("<html");
string body = now.substr(start);
int idx = 0;
while(idx < body.size()) { //기본 점수 계산 소문자로 찾기
int pos = body.find(tolower(word[0]), idx);
if(pos == string::npos) break; //단어 없으면 종료
if(pos + word.size() > body.size()) break; //범위 벗어나면 종료
string tmp = body.substr(pos, word.size()); //길이를 벗어나면 break
if(word.size() == tmp.size() && isSame(word, tmp)) {//길이가 같은 문자열 저장
if(!isalpha(body[pos-1]) && !isalpha(body[pos + word.size()])) //앞 뒤로 알파벳이 없을 때 증가
basic[i]+=1;
}
idx = pos+1;
}
idx = 0;
while(idx < body.size()) { //기본 점수 계산 대문자로 찾기
int pos = body.find(toupper(word[0]), idx); //첫 글자가 같은 위치 검색
if(pos == string::npos) break; //단어 없으면 종료
if(pos + word.size() > body.size()) break; //길이를 벗어나면 break
string tmp = body.substr(pos, word.size()); //길이가 같은 문자열 저장
if(word.size() == tmp.size() && isSame(word, tmp)) { //사이즈도 같고 같은 문자일 때
if(!isalpha(body[pos-1]) && !isalpha(body[pos + word.size()])) //앞 뒤로 알파벳이 없을 때 증가
basic[i]+=1;
}
idx = pos+1; //다음 위치부터 다시 검색
}
idx = 0;
while(idx < body.size()) { //링크 주소 찾기
int start = body.find("<a href=\"https://", idx);
if(start == string::npos) break;
start += 9;
int end = body.find("\"", start);
string link = body.substr(start, end - start); //링크 문자열
links[link].insert(i); //자신을 가리키는 페이지 인덱스에 insert
linknum[i]++; //현재 페이지의 링크 수 증가
idx = end;
}
}
for(int i = 0; i < pages.size(); i++) { //최고점 찾기
double score = basic[i]; //기본 점수
for(auto it = links[url[i]].begin(); it != links[url[i]].end(); it++) {
score += ((basic[*it]) / linknum[*it]); //링크 점수 더하기
}
if(mnum < score) { //최대값 갱신
mnum = score;
answer = i;
}
}
return answer;
}index - url 매핑한 url 배열, 기본점수를 저장할 basic 배열, 각 노드의 외부 링크 수를 저장할 linknum배열, 자신을 가리키는 링크의 인덱스를 저장할 links map을 선언하였다.
주의할 점과 실수한 부분
이 문제는 문자열을 파싱하는 부분이 조금 까다로웠고 점수가 double형으로 계산되어야 했다. 처음 int형으로 basic을 저장하고 캐스팅하여 점수를 계산하였을 때 몇 개의 테스트케이스를 통과하지 못했었다. 그 다음 최대값을 저장한 mnum 변수도 int형으로 선언되어있었는데 이것 때문에 8번, 17번만 통과를 하지 못하고 있었다. 이 실수를 모르고 계속 다른 부분에서 오류를 찾아 시간낭비를 많이 했다. mnum도 double로 바꾸는 순간 모든 테스트 케이스도 통과할 수 있었다.
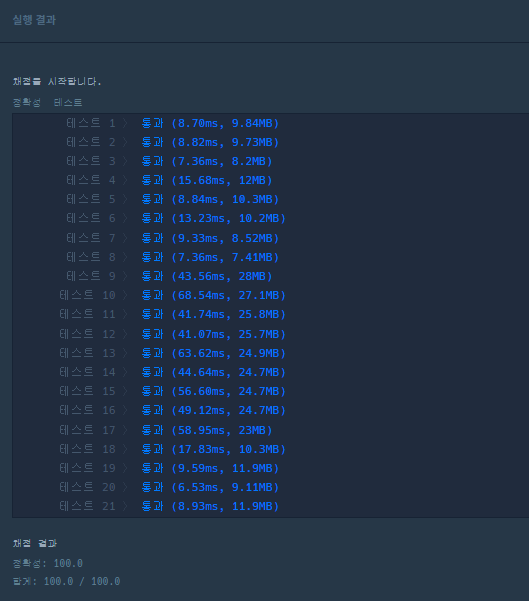
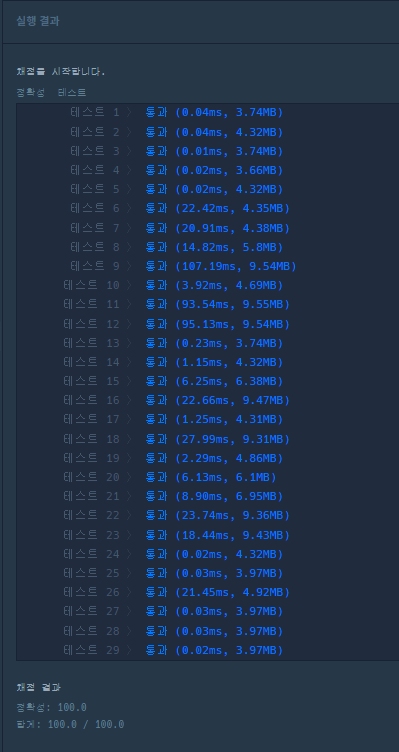
채점 결과

'알고리즘 > 프로그래머스' 카테고리의 다른 글
| [C++] 프로그래머스 외벽 점검 풀이 (0) | 2021.08.18 |
|---|---|
| [C++] 프로그래머스 블록 이동하기 풀이 (0) | 2021.08.18 |
| [C++] 프로그래머스 순위 검색 풀이 (0) | 2021.08.06 |
| [C++] 프로그래머스 110 옮기기 풀이 (0) | 2021.08.06 |
| [C++] 프로그래머스 모두 0으로 만들기 풀이 (3) | 2021.08.05 |